Policies
Conexus CQL is a revolutionary data transformation platform re-thought for the cloud. Conexus can speed up every M&A integration and save many that would otherwise fail.
Introduction
Before CQL, there was no solution that gave you a unified view of all your data or that allowed you to migrate, transform, or aggregate your data across platforms.
Your data is always living somewhere, embedded in the proprietary systems, standards, and semantics of one service, which don’t translate to other services. But some of your data may be on these other cloud platforms. Or you might work with a partner or client that uses a different platform. Or you want the functionality of one platform for certain data and the functionality of another platform for other data. CQL is the only tool that offers true interoperability—visibility of all your data across platforms and the ability to work with that data interchangeably.
CQL for users of Graph DBs
Fact 1
There are a huge number of graph database vendors with non-interoperable products (grakn, neo4j, etc); over 70% of Fortune 500 companies use these products.
Fact 2
Almost all enterprises have lots of different graphs, usually in multiple vendors, and need to operate over many of the graphs at once.
Fact 3
Facts 1 and 2 create the potential for data pandemonium at Uber and similar international enterprises.
Fact 4
CQL, using category theory, allows point-to-point migration of data between graph vendors, as well as the ability to merge graphs.
Fact 5
CQL, as an ETL tool for structured data transformation, holds no data itself: it is merely a connector, or “conexus”, to connect existing data stores (so it is pay as you go and requires no change in infrastructure).
Key idea
Conexus is not another graph DB vendor. We connect your graphs so that you can get more value out of the data you already have – see our case study with Uber.
SQL query migrator for AWS cloud migration
Fact 1
In a typical Amazon cloud migration, SQL databases (e.g. on Oracle) are migrated to specialized, heterogeneous AWS databases (graph, key-value, JSON, etc.).
Fact 2
Although using specialized AWS databases can save money for particular tasks, IT functions that cross databases (e.g. auditing) must take AWS heterogeneity into account, a friction that was not present before AWS cloud migration.
Fact 3
Facts 1 and 2 mean that AWS cloud migrations are often counterproductive, sometimes disastrously so.
Fact 4
CQL, by automatically re-writing SQL queries to operate on these heterogeneous data stores (with 100% compile-time guarantees of semantics preservation and perfect provenance), eliminates this friction outright.
Key idea
We migrate your data to AWS in such a way that you can re-use the SQL queries you already have and actually achieve ROI with AWS (without being locked into it). See our (technical) case study with NIST about this technology as applied to manufacturing supply chain management.
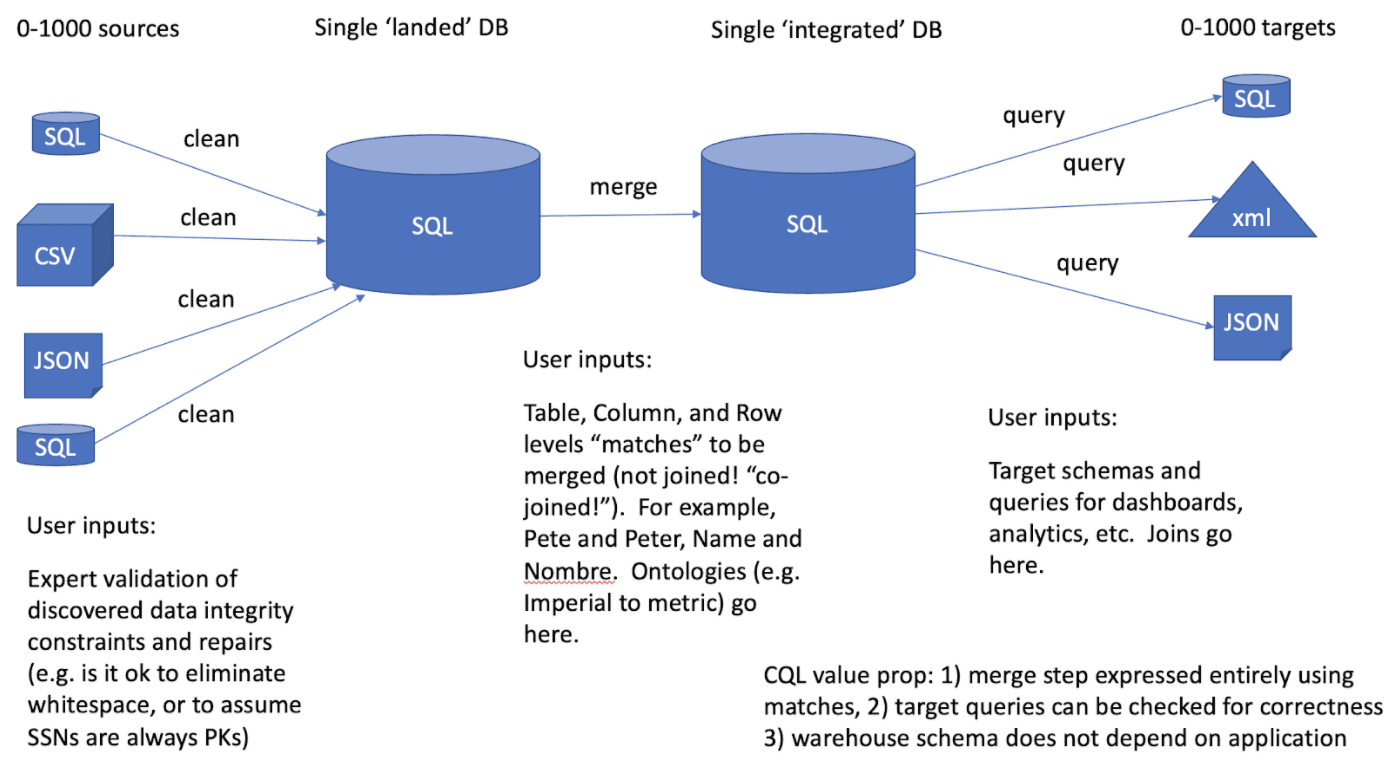
CQL for universal data warehousing to reduce data lake size
Problem
An enterprise is storing data in a data lake with substantial semantic overlap, and the overlaps are leading to data anomalies during analysis and reporting (Pete and Peter are two different people, 1in isn’t 2.54cm, Name isn’t Nombre, etc.).
Solution
CQL, by formalizing the relationships inside your data, provides a universal data warehouse instead of (or inside of) a data lake, removing these anomalies so your data scientists don’t have to. CQL eliminates these anomalies before the data is used, rather than finding errors only when the project fails.
Value proposition
Conexus is not another “match finder”: we use the domain expertise and data/column matches you already have to build a data warehouse that is provably optimal, clean, and as small as possible integrated with respect to your matches (ontology) with 100% compile time reliability enabled by AI techniques. Case study: See our (technical) whitepaper for financial reporting data warehousing.